Redis数据结构源码解析(六) 快速列表

前言
在前面分别介绍了:双向链表和压缩列表,两者作为老版本中List类型的底层实现,但是在3.2版本后被本文主角取代。
基于两者的优劣,衍生了本文的主角——快速列表
概念
quickList 实际上是 zipList 和 linkedList 的混合体,它将 linkedList 按段切分,每一段使用 zipList 来紧凑存储,多个 zipList 之间使用双向指针串接起来。
简单来说:将多个压缩列表组成一个链表就是快速列表了。
为什么这么做
zipList 实现是基于数组,相比较双向链表最大的提升就是减少了内存的碎片,这点对于一个基于内存的高性能存储时很重要的,但是它带来的问题也很严峻,列表元素当达到一定的量级就可能出现问题:
- 很难找到那么大的连续内存空间:如果一个压缩列表无限大,虽然服务器可用内存好友但是因为没有足够的连续内存也会出现问题。
- 当列表足够大时,每一次的插入和删除操作需要频繁的申请和释放内存,产生大量的数据拷贝。
所以遵循着分治原则,将一个大的列表拆分成N个小的列表通过指针首尾相接就有了—— QuickList 快速列表。
基本结构
quicklist
1 | typedef struct quicklist { |
quicklistNode
1 | typedef struct quicklistNode { |
- prev: 指向链表前一个节点的指针。
- next: 指向链表后一个节点的指针。
- zl: 数据指针。如果当前节点的数据没有压缩,那么它指向一个ziplist结构;否则,它指向一个quicklistLZF结构。
- sz: 表示zl指向的ziplist的总大小(包括
zlbytes,zltail,zllen,zlend和各个数据项)。需要注意的是:如果ziplist被压缩了,那么这个sz的值仍然是压缩前的ziplist大小。- count: 表示ziplist里面包含的数据项个数。这个字段只有16bit。稍后我们会一起计算一下这16bit是否够用。
- encoding: 表示ziplist是否压缩了(以及用了哪个压缩算法)。目前只有两种取值:2表示被压缩了(而且用的是LZF压缩算法),1表示没有压缩。
- container: 是一个预留字段。本来设计是用来表明一个quicklist节点下面是直接存数据,还是使用ziplist存数据,或者用其它的结构来存数据(用作一个数据容器,所以叫container)。但是,在目前的实现中,这个值是一个固定的值2,表示使用ziplist作为数据容器。
- recompress: 当我们使用类似lindex这样的命令查看了某一项本来压缩的数据时,需要把数据暂时解压,这时就设置recompress=1做一个标记,等有机会再把数据重新压缩。
- attempted_compress: 这个值只对Redis的自动化测试程序有用。我们不用管它。
- extra: 其它扩展字段。目前Redis的实现里也没用上。
基本操作
插入
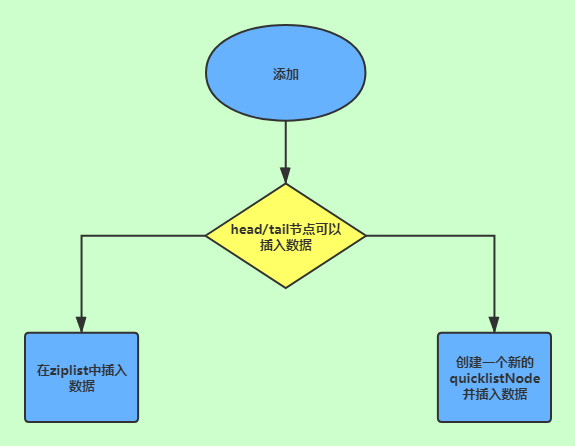
quicklist可以选择在头部或者尾部进行插入(quicklistPushHead和 quicklistPushTail),而不管是在头部还是尾部插入数据,都包含两种情况:
- 如果头节点(或尾节点)上ziplist大小没有超过限制(即
_quicklistNodeAllowInsert返回1),那么新数据被直接插入到ziplist中(调用ziplistPush)。 - 如果头节点(或尾节点)上
ziplist太大了,那么新创建一个quicklistNode节点(对应地也会新创建一个ziplist),然后把这个新创建的节点插入到quicklist双向链表中。
总结
- 一个基于压缩列表和链表实现的数据结构,本质用于解决单纯的链表和压缩列表所遇到的一些内存上问题。
致谢
- 本文标题:Redis数据结构源码解析(六) 快速列表
- 本文作者:SunRan
- 创建时间:2022-01-20 09:25:37
- 本文链接:https://lksun.cn/2022/01/20/Redis数据结构源码解析-六-快速列表/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
评论