
对比HashMap
字典的使用和底层与Java中的HashMap还是很像的,比较特殊的就是扩容方式。
基本结构
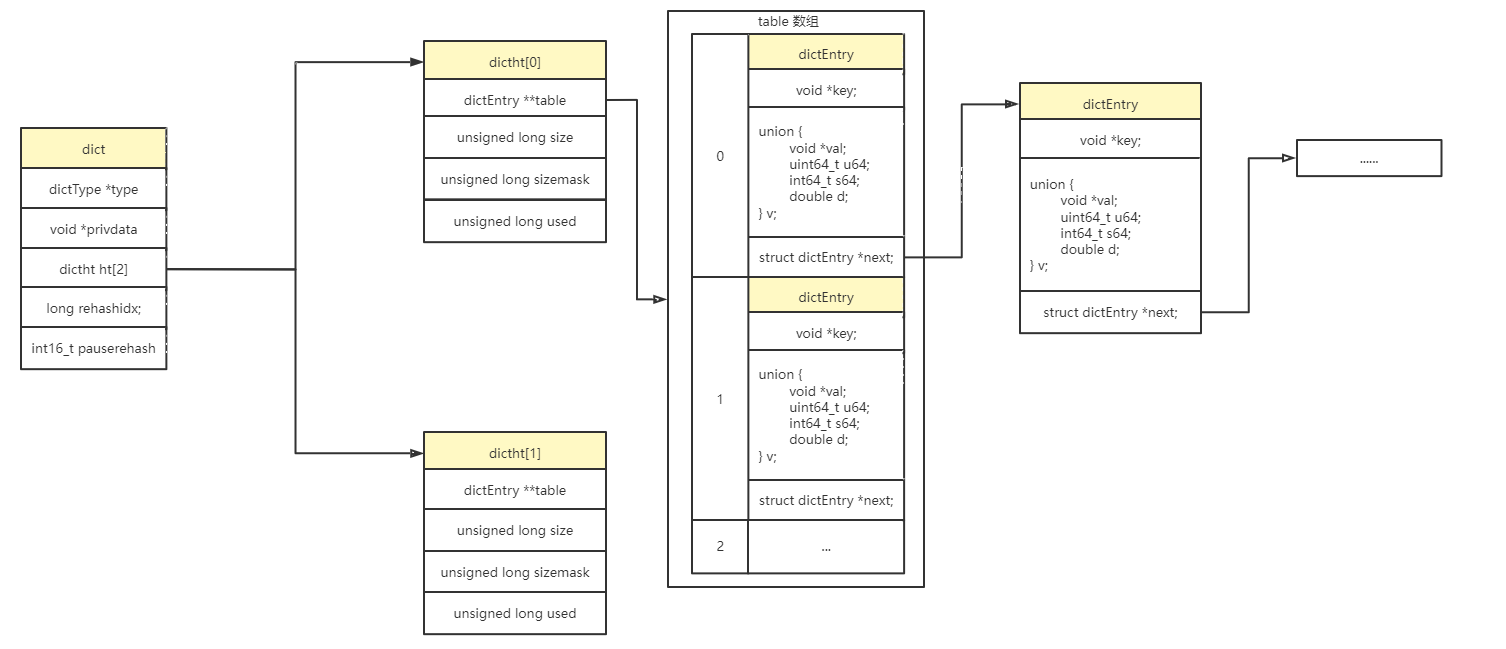
dict
1 | typedef struct dict { |
dictht
1 | typedef struct dictht { |
dictEntry
1 | typedef struct dictEntry { |
如何应对Hash冲突
既然使用了Hash表,就逃不掉Hash冲突的问题。
Java中的解决方式
HashMap 使用了数组+链表+红黑树的底层结构,每一个节点对象都会有
next属性,从而形成一个链表结构。当链表长度大于8时会升级为红黑树。
1 | static class Node<K,V> implements Map.Entry<K,V> { |
其实这叫拉链法或者叫链地址法
拉链法
把具有相同散列地址的关键字(同义词)值放在同一个单链表中,称为同义词链表。
添加元素
dictAdd
1 | /* Add an element to the target hash table */ |
dictAddRaw
1 | dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing) |
其中的 rehash 会在扩容中讲述。
最关键的一个点:ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];。在进行 rehash放入 ht[1]反之则 ht[0]
查询操作
dictFetchValue
1 | void *dictFetchValue(dict *d, const void *key) { |
dictFind
1 | dictEntry *dictFind(dict *d, const void *key) |
几个关键点:
idx = h & d->ht[table].sizemask;:在日常开发中这种场景我们更喜欢使用取余(%),因为快、方便;在HashMap中使用的就是取余,但是限制了数组长度为2的幂+位运算快速取余;在Redis中则是使用了掩码进行&运算
dictGetVal
1 |
扩容操作
其实在前面的操作中已经看到了一些关于扩容的影子,例如什么是 rehash?为什么要有 ht[1]和 ht[2]
其实这些都是为了实现一个机制——渐进式扩容。
什么是渐进式扩容
就好像一口吃不成胖子,一口气吃太多吃太快对胃不好,要慢慢吃慢慢长胖
Redis中Hash类型使用了渐进式的扩容机制,因为遇到大Key时会对性能造成巨大的影响。
所以在dict对象中有这样一个属性:dictht ht[2],存放了一个长度为2的数组。
ht[0],是存放数据的table,作为非扩容时容器;
ht[1],只有正在进行扩容时才会使用,它也是存放数据的table,长度为ht[0]的两倍。扩容时,单线程A负责把数据从
ht[0]复制到ht[1]中。如果这时有其他线程
进行读操作:会先去ht[0]中找,找不到再去ht[1]中找。
进行写操作:直接写在ht[1]中。
进行删除操作:与读类似。
扩容流程
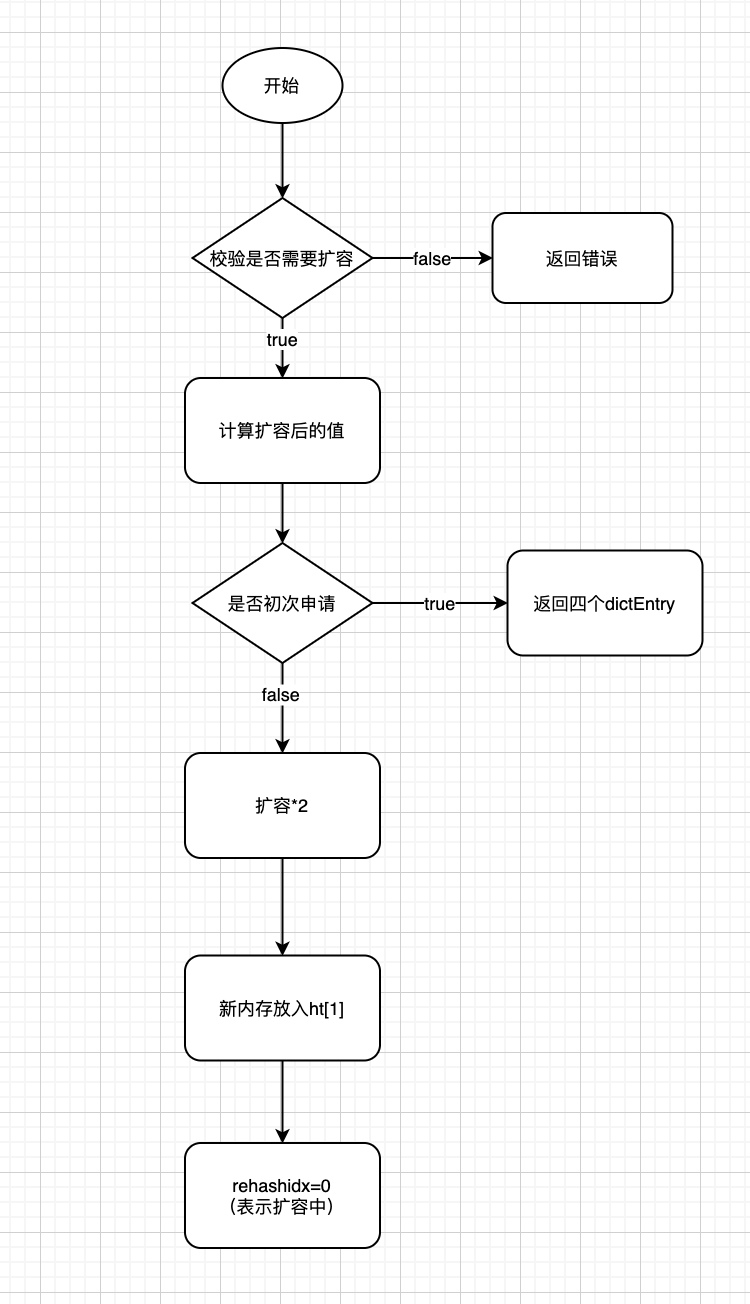
1 | int _dictExpand(dict *d, unsigned long size, int* malloc_failed) |
redis中的key可能有成千上万,如果一次性扩容,会对性能造成巨大的影响,所以redis使用渐进式扩容,每次执行插入,删除,查找,修改等操作前,都先判断当前字典的rehash操作是否在进行,如果是在进行中,就对当前节点进行rehash操作,只执行一次。除此之外,当服务器空闲时,也会调用incrementallyRehash函数进行批量操作,每次100个节点,大概一毫秒。将rehash操作进行分而治之。
渐进式rehash流程
rehash的准备工作
- 设置字典的
rehashidx为0,标识着rehash的开始; - 为
ht[1]->table分配空间,大小至少为ht[0]->used的两倍;
dictRehash
1 | int dictRehash(dict *d, int n) { |
首先梳理
dictRehash方法,N和N*10的关系。- 一次
dictRehash方法最多迁移N个桶。 - 但是每次
dictRehash不一定都是需要迁移的,可能有些桶的数据为NULL,遇到N*10次空桶则结束(为什么这么做?不能无休止的让他遍历下去,防止过久的阻塞)
- 一次
关于头插法
de->next = d->ht[1].table[h];首先将ht1中的de对象的尾节点- 再将de对象设置到
d->ht[1].table[h]
总结
Redis 中的数据库和哈希键都基于字典来实现。
字典是由键值对构成的抽象数据结构。
Redis自己实现了一套哈希表的逻辑,与Java中的HashMap相似但是不完全一样,拿两者比较的总结一下。
- 两者都通过拉链法解决了Hash冲突问题,只不过HashMap有升级红黑树的机制,Redis没有
- Redis实现了逐渐式扩容,不会一下子把所有Key进行迁移(遇到大Key可能出现异常);HashMap就是普通的迁移。
- 逐渐式扩容使Redis底层需要使用到两个Hash表,一般情况下只使用 0 号哈希表,只有在 rehash 进行时,才会同时使用 0 号和 1 号哈希表。
- HashMap通过指定规则:数组长度为2的幂+位运算进行取数组下标;Redis使用掩码的方式。
- HashMap在1.8之前为头插法,之后为尾插法;Redis中一直为头插法。
致谢
- 本文标题:Redis数据结构源码解析(二) 字典
- 本文作者:SunRan
- 创建时间:2022-01-19 11:07:28
- 本文链接:https://lksun.cn/2022/01/19/Redis数据结构源码解析-二-字典/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!