Redis数据结构源码解析(〇) 五大数据类型

前言
本文不介绍具体使用,已底层实现为主。先宏观介绍下实现方式具体实现后续文章介绍。
数据类型
- 字符串 String
- 列表 List
- 集合 Set
- 有序集合 ZSet
- 哈希 Hash
数据编码
1 |
底层实现
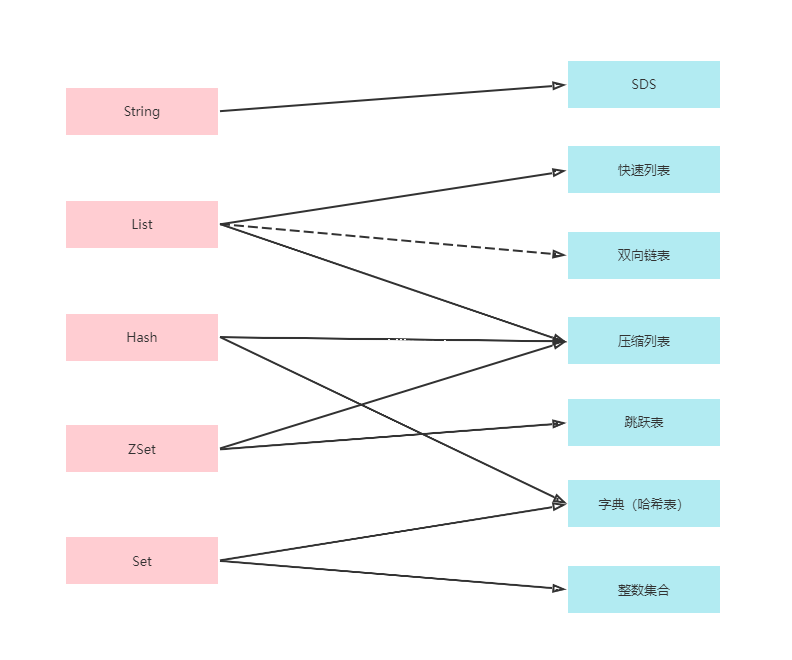
一 、字符串
使用了三种作为底层的实现:
embstr(OBJ_ENCODING_EMBSTR)
长度小于44字节的字符串,该编码中
RedisObject、SDS放置在连续的内存中。row(OBJ_ENCODING_RAW)
长度大于44字节,除此之外与
OBJ_ENCODING_EMBSTR区别仅在于是否为连续内存int(OBJ_ENCODING_INT)
有时候我们会在String寸INT类型的自然数,例如一个手机号如果为字符串则需要11字节,如果使用long long 只需要8字节。
3中的 Int没什么好说的属于基本数据类型,1和2都涉及到SDS,这也是Redis中很基础的一个对象。
二 、列表
使用了三种作为底层的实现:
- 双向链表(OBJ_ENCODING_LINKEDLIST)
- 链表节点指针比较多,内存浪费。
- 链表会造成内存碎片
- 压缩列表(OBJ_ENCODING_ZIPLIST)
- 底层为数组实现,解决了内存碎片问题,不需要指针
- 当元素很多时,可用内存明明足够,但是因为没有足够大的连续内存而出问题
- 数组的新增、删除牵一发动全身,需要整个列表进行数据操作
- 快速列表(OBJ_ENCODING_ZIPLIST)
- 基于压缩列表和链表实现,解决了压缩列表存在的一些问题,通过分治思想把很大的列表拆分为多个
3.2版本之后弃用了双向链表改为快速列表。
那么什么时候使用压缩列表什么时候使用快速列表?
- 所有字符串元素的长度都小于 64 字节并且保存的元素数量小于512个的列表使用压缩列表
- 存在字符串元素长度大于64或元素个数大于512个使用快速列表
三、Hash
使用了两种作为底层的实现:
- 字典(哈希表)(OBJ_ENCODING_HT)
- 压缩列表(OBJ_ENCODING_ZIPLIST)
关于两者的选择其实比较简单:
因为压缩列表比字典更节省内存, 所以程序在创建新 Hash 键时, 默认使用压缩列表作为底层实现, 当有需要时, 程序才会将底层实现从压缩列表转换到字典。
- 总长度超过512字节或者单个元素长度大于64使用字典
- 总长度小于512字节或者单个元素长度小于64使用压缩列表
四、Set
使用了两种作为底层的实现:
- 整数集合 (OBJ_ENCODING_INTSET)
- 字典(哈希表)(OBJ_ENCODING_HT)
关于两者的选择:
Redis没有规定Set可存放的数据类型为什么,可能遇到与String同样的问题。存储一个手机号,使用字符串和long类型内存的占用是完全不一样的。
真的是能省就省
- 集合对象保存的所有元素都是整数值且元素数量不超过
512个使用整数集合 - 总长度超过512字节或者单个元素长度大于64的使用字典
- 遇到如下情况会立刻发生转换
- 往集合中添加了非整型变量会转换为字典
五、ZSet
使用了两种作为底层的实现:
- 跳跃表(OBJ_ENCODING_SKIPLIST)
- 压缩列表(OBJ_ENCODING_ZIPLIST)
两者的选择也在于内存的使用上:
在大量元素的集合中使用跳跃表可以更快的查询,但是如果数量不多还要存储大量的多层索引会造成内存的浪费。
zset会根据zadd命令添加的第一个元素的长度大小来选择编码方式:满足zset_max_ziplist_entries的值不为0,第一个元素的长度小于server.zset_max_ziplist_value,使用压缩列表,否则就是跳跃表。- 待新加的新的字符串长度超过
zset_max_ziplist_value(默认值64)时或者ziplist保存的节点数量超过server.zset_max_ziplist_entries(默认值128)时使用skiplist。
总结
| 数据类型 | String | List | Hash | Set | ZSet |
|---|---|---|---|---|---|
| SDS | √ | ||||
| 快速列表 | √ | ||||
| 双向链表 | √ | ||||
| 压缩列表 | √ | √ | √ | ||
| 跳跃表 | √ | ||||
| 字典(哈希表) | √ | √ | |||
| 整数集合 | √ |
致谢
- 本文标题:Redis数据结构源码解析(〇) 五大数据类型
- 本文作者:SunRan
- 创建时间:2022-01-18 00:00:00
- 本文链接:https://lksun.cn/2022/01/18/Redis数据结构源码解析-〇-五大数据类型/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
评论